Cold Start Optimization
The RaBitQ (vchordrq) index is loaded from the disk during the first query. This is why the cold start is much slower.
If the shared buffer is sufficient, the index can be cached in memory, which speeds up subsequent queries.
In VectorChord, we have two ways to improve cold start performance. Let's dive in!
Indexing Prewarm
To improve performance for the first query, you can try the following SQL that preloads the index into memory.
-- vchordrq_prewarm(index_name) to prewarm the index into the shared buffer
SELECT vchordrq_prewarm('gist_train_embedding_idx')INFO
The runtime of vchordrq_prewarm is correlated to the number of rows, and can consume several minutes for large table (>
Prefetch Mode since v0.4.0
TIP
This feature is enabled by default. Any query can be benefit from prefetching with VectorChord v0.4.0 and later versions.
PostgreSQL 17 has introduced a new streaming I/O API for more efficient sequential I/O. Take advantage of it, a sequential scan on a table will be much faster.
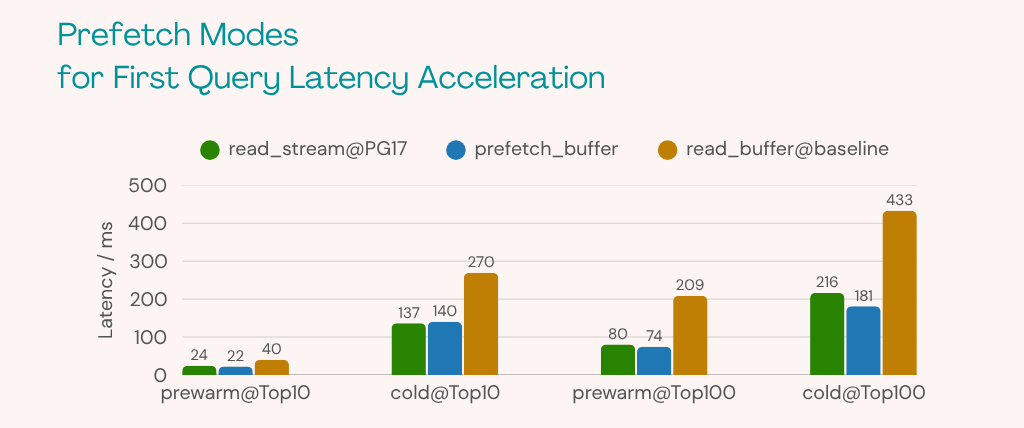
In VectorChord, we implemented two prefetch methods: A simple one, prefetch_buffer, and read_stream, which uses the streaming I/O API. Both methods are much faster than the previous behavior, read_buffer.
They can be set by vchordrq.io_rerank and vchordrq.io_search:
| Prefetch Mode | Description | Supported on PG Version |
|---|---|---|
| read_stream | Advanced streaming prefetch by streaming I/O API | PostgreSQL 17+ only |
| prefetch_buffer | Simple prefetching using PostgreSQL's buffer prefetch mechanism | Any |
| read_buffer | Basic buffer reading without prefetching | Any |
If you are using PostgreSQL 16 or an earlier version, the prefetch_buffer can also help you.
Furthermore, the Asynchronous I/O which will in PostgreSQL 18 will make read_stream more advantageous.
Based on our experimental results, the first query latency can be reduced by:
- 2-5 times with prewarm
- 2-3 times with prefetch